Reinforcement Learning Simulator
| Parameter | Value |
|---|---|
| γ | |
| α | |
| ε |
A Javascript-based jumping game simulator being solved with a simple tabular Q-learning reinforcement learning agent. An agent has two actions: to jump or not to jump. The state is comprised of the enemy's location and an indicator variable of whether the agent is in the air or not. If an agent collides with the enemy, the agent receives a reward of -1. Otherwise, the agent receives a reward of 0.
The results of 1000 epochs show an evident increase in performance by the agent:
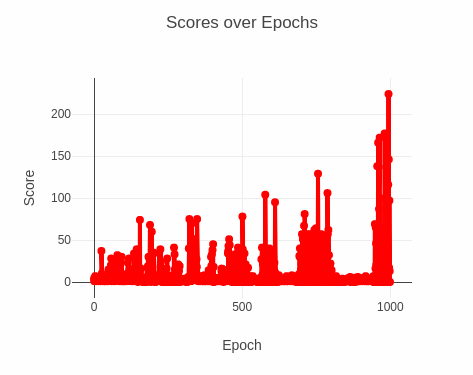
Interesting to note that, over the course of the simulation, there are several long periods of the model getting stuck with low scores. My best guess would be that the model has yet to converge and that these bad periods are a result of the model updating toward a suboptimal parameter configuration, realizing its mistake, and learning to fix itself. Perhaps with a higher learning rate, we'd have fewer of these incidences.